 +420 601 126 669
+420 601 126 669 obchod@mytimi.cz
obchod@mytimi.cz

 Marketing
Marketing
SEO: Jak se zbavit nežádoucího obsahu ve vyhledávačích aneb efektivní indexování
5. 2. 2024
SEO
Přečteno 5650 x
Říkáte si, proč by chtěl nějaký blázen odebírat stránku z výsledků vyhledávání, když o místa v SERPu zuří nelítostný boj? Důvodů může být celá řada. Sepsali jsme pro vás nejen proč, ale především jak odebrat stránku z indexu – způsobů je hned několik.

Proč chtít vyřadit stránky z indexu?
Během indexace boti (říká se jim „crawlers“ nebo „spiders“), které používá vyhledávač, procházejí webové stránky, analyzují jejich obsah a ukládají si je do databáze – indexu. Díky tomu o vaší stránce vyhledávač ví a může ji doporučit ve výsledcích vyhledávání v souvislosti s relevantním hledaným dotazem. Pokud boti při analýze stránky narazí na URL odkaz, následují ho a danou stránku také analyzují (a tak pořád dokola). Podrobněji jsme princip indexace rozepsali v článku.
Počet jednotlivých stránek vašeho webu, které vyhledávač dokáže za určité časové období projít a uložit do databáze, je ale omezený – tzv. crawl budget. Proto potřebujete v případě, že máte rozsáhlý web, kalkulovat, které stránky je pro vás výhodné indexovat a které naopak ne.
Odebrat stránku z indexu můžete chtít také například:
- v případě, že obsahuje zastaralé, interní nebo duplicitní informace,
- pokud jsou přístupné jen určitým uživatelům (například po registraci),
- ve vývoji, kdy ji ještě nechcete zpřístupnit veřejnosti,
- když se jedná o landing page, která je určená jen jako cílová stránka pro reklamy.
Některé stránky se také k indexaci nehodí už jen z principu – jsou to třeba stránky související s provedením nákupu jako je obsah nákupního košíku, volba dopravy a vyplňování doručovacích údajů.
Tip: Přečtěte si také o technickém SEO a správném použití JavaScriptu. Pokud totiž boti stránky s JavaScriptem nepřečtou, nepošlou je samozřejmě ani k zaindexování.
Jak funguje robots meta tag?
Meta tag robots je základní nástroj pro řízení toho, jak vyhledávače interagují s vaší webovou stránkou. Tento tag vám umožňuje specifikovat, jestli vyhledávače mohou indexovat danou stránku (pomocí atributu noindex), zda mohou sledovat odkazy na této stránce (použitím nofollow), nebo zda mají archivovat obsah stránky (noarchive).
Abyste mohli přidat do HTML robots meta tag, stačí umístit následující kód do hlavičky (head) HTML dokumentu:
<meta name="robots" content="noindex, nofollow, noarchive">
- noindex – říká botům, že nemají stránku, na které se tento tag nachází, indexovat. Ta se následně nebude zobrazovat ve výsledcích vyhledávání.
- nofollow – říká vyhledávačům, aby nebraly v úvahu odkazy na této stránce při hodnocení odkazů. To znamená, že odkazy vycházející z této stránky nebudou mít vliv na hodnocení odkazovaných stránek v rámci vyhledávačů. Podle odkazů nebude hodnocená ani samotná stránka, na které je nonfollow umístěné. Tento tag se často používá, aby se zabránilo link spamu na fórech a v komentářích, kam uživatelé často přidávají vlastní odkazy.
- noarchive – tento příkaz instruuje vyhledávače, aby neukládaly cache kopii stránky. To znamená, že uživatelé nebudou mít přístup k uloženým verzím této stránky přes funkce jako „Uložená kopie“ ve vyhledávači Google. Hodí se pro stránky, které často aktualizujete.
Tyto příkazy můžete samozřejmě libovolně kombinovat. Třeba index a nofollow – robot stránku zaindexuje, ale nebude sledovat odkazy, které z ní vedou. Nebo naopak noindex a follow říká botům, aby tuto stránku sice neindexovali, ale procházely další stránky, na které odkazujete. A tak podobě.
Více se o použití nonindex nebo obecně robots meta tag můžete dočíst přímo od Googlu.
Co je robots.txt?
Kromě nofollow je dalším způsobem, jak můžete botům sdělit, zda mají stránku procházet soubor robots.txt. Jeho použití může pomoci zabránit zbytečnému zatížení serveru a přispět tomu, aby boti prošly pouze stránky, které chcete. Není to ale stoprocentní. Když na stránku například vede autoritativní odkaz, bot ho bude následovat a stránku stejně projde.
Kromě toho je soubor robots.txt také důležitý pro SEO. Doporučuje se, aby obsahoval odkaz na soubor sitemap, který vyhledávačům usnadní orientaci na webu.
Google radí používat místo robots.txt spíše noindex tag. Jenže v případě jeho použití nešetříte zmíněný crawl budget, protože bot musí stránku navštívit, aby si na ní tento tag následně přečetl a zjistil, že ji nemá indexovat. Zatímco při použití instrukcí z robots.txt, bot už dopředu ví, že danou stránku nemá vůbec procházet.
Pokud robots.txt na webu nemáte, bere to bot jako pokyn, že může procházet všechny stránky. Pro zamezení procházení určitých částí webu tedy vytvořte soubor robots.txt v kořenovém adresáři vašeho webu a specifikujte, které adresáře nebo stránky by neměly být procházeny. Může to vypadat např. takto:
User-agent: *
Disallow: /privatni/
Disallow: /test/
V tomto příkladu User-agent: * znamená, že pokyny platí pro všechny vyhledávače. Disallow: /privatni/ brání procházení jakékoli stránky nebo podstránky v adresáři /privatni/, a podobně pro adresář Disallow: /test/. „User-agent“, ale může být Googlebot nebo Seznambot a za „Disallow“ můžete pochopitelně vložit jakýkoliv adresář.
Pozor: Jak už jsme zmínili, použitím robots.txt botům zcela nezamezíte v pocházení a potažmo ani indexaci. Ne všichni boti berou instrukce z tohoto souboru v potaz, zvláště pokud se jedná o méně známé vyhledávače. Nastavení v souboru taky nemusí nutně zabránit zobrazení stránky ve výsledcích vyhledávačů, pokud vedou na tuto stránku odkazy z jiných webů. Nedoporučujeme proto používat jenom robots.txt, ale kombinovat jeho použití s dalšími metodami. Důležité je také vědět, že robots.txt žádným způsobem boty „nepřivolává“, takže se samotnou indexací vám nepomůže, pouze zakazuje a informuje.
Proč nastavit x-robots-tag?
HTML záhlaví x-robots-tag má podobnou funkci jako robots meta tag v HTML, ale jeho vložením ho aplikujete na úrovni serveru. To znamená, že můžete ovlivnit indexaci nejen pro jednotlivé HTML stránky, ale i pro jiné typy souborů, jako jsou soubory PDF, XML nebo třeba obrázky. U nich jiným způsobem indexaci nezakážete.
Používají se zde stejné příkazy jako u meta tagu robots – tedy noindex, nofollow nebo noarchive. Nastavení záhlaví x-robots-tag v konfiguračním souboru serveru Apache (v .htaccess), tedy může být třeba takové:
Header set X-Robots-Tag "noindex"
Tento příklad zakazuje indexaci souborů PDF a JPG.
Aby tato metoda fungovala, potřebujete mít správně nakonfigurovaný webový server. Je tedy žádoucí mít přístup k nastavení serveru nebo spolupracovat s jeho administrátorem. Manipulace s HTTP záhlavími je také pokročilejší technika a vyžaduje určitý stupeň technických znalostí, svěřte tedy raději nastavení x-robots-tag někomu zkušenému.
Tip: Podívejte se i na tipy, jak zlepšit technické SEO včetně optimalizace obrázků nebo URL adres.
Odstranění z Google Search Console
Dočasné odstranění URL odkazu z výsledků vyhledávání Google poskytuje i nástroj v Google Search Console. Důležité je však ono slovíčko „dočasné“ a fakt, že se toto odstranění týká pouze vyhledávače Google. I tak ale může být tento nástroj užitečný, když potřebujete rychle z vyhledávání skrýt třeba stránku s neplatnými informacemi nebo zbožím, které nebudete mít nějakou dobu na skladě.
Postup je následovný:
- Zkopírujete si URL adresu stránky, kterou budete chtít vyřadit z indexu.
- Otevřete si svůj účet v Google Search Console.
- V levém horním rohu vyberete web, na kterém se nachází daná podstránka.
- V bočním menu v kategorii „Index“ uvidíte možnost „Odebrání“, klikněte na ni.
- Zvolte možnost „Dočasná odstranění“ a po kliknutí na „Nová žádost“ zadejte adresu, kterou jste si na začátku zkopírovali, a odešlete požadavek na dočasné odstranění stránky z Indexu. (Raději se dvakrát ujistěte, že je zadaná URL adresa správná, ať omylem nevydaříte nějakou jinou.)
Dočasné odstranění v praxi znamená, že je stránka pro vyhledávače neviditelná po dobu přibližně 6 měsíců, poté může být znovu indexována. Do té doby máte čas stránku patřičně upravit nebo ji trvale skrýt pomocí jedné z metod uvedených výše. Nezapomínejte ale, že na ostatních vyhledávačích bude stále dohledatelná.
Tip: Zjistěte o SERP všechno, co potřebujete vědět. Podrobně jsme si na výsledky vyhledávání posvítili v tomto článku.
Pokud se stránka dočasně vyřadí z indexu, má to vliv na její SEO v případě, že se po čase opět vyhledávačům zpřístupní?

Milan Fafek
SEO specialista myTimi
Pokud chceme trvale odebrat stránku z indexu (výsledků vyhledávání) je potřeba na stránku nasadit direktivu noindex, nofollow. Následně ji odeslat k prozkoumání do Google Search Console aby si nové informace o stránce Google zjistil a zpracoval. Pokud se jedná o více stránek, doporučujeme vytvořit samostatnou sitemap a uložit na ní odkaz v absolutním tvaru do souboru robots.txt (jakmile se stránky deindexují je možné odkaz na sitemap odebrat).
Máte odstraněno – a co dál?
Především je potřeba kontrolovat, jestli jsou stránky, které jste odstranili z indexu pro vyhledávače opravdu skryté, a zda se naopak zobrazují ty, co potřebujete.
V případě Seznamu to můžete zjistit pomocí operátoru info a za ním příslušnou URL adresou, která vás zajímá. Např.:
Info:https://www.mytimi.cz/seo-optimalizace-webu/
Pokud se stránka objeví ve výsledcích vyhledávání, je zaindexovaná. A pokud ji chcete skrýt, můžete použít jeden z výše popsaných postupů.
Google tento způsob ověřování už nepodporuje, proto musíte použít kontrolu pomocí URL inspection tool v Google Search Console, ta se hodí v případě kontroly menšího množství stránek. Pokud chcete kontrolovat stovky z nich naráz, můžete využít například Fulltext Index Checker v Marketing Miner.
Můžete také zadat do vyhledávání příkaz site:[adresa webu], zjistit, kolik stránek z vašeho webu je zaindexovaných a projít si jejich seznam.
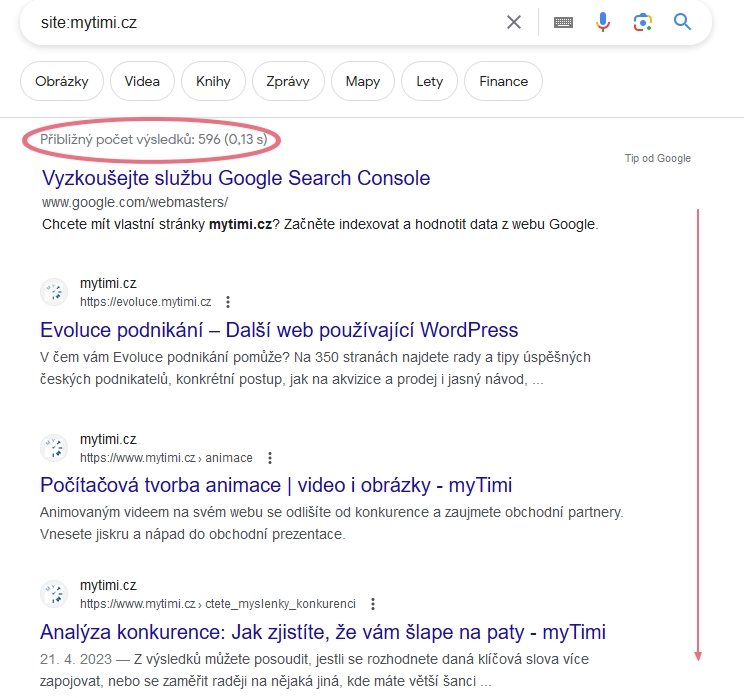
Na rozdíl od příkazu info tak můžete hromadě kontrolovat větší počet stránek.
Negativní dopady na SEO
Pokud indexaci stránek nevěnujete pozornost, může to mít negativní dopady na SEO, zejména pokud máte na webu stránky s duplicitním či málo kvalitním obsahem nebo stránky porušující směrnice vyhledávačů. Takové raději vyřaďte z indexování (nebo je na webu vůbec nemějte).
Ujistěte se také, že nemáte v souboru sitemap umístěné stránky s erorrem 404 a že na ně nikde na webu neodkazujete.
Indexování zkvalitní váš web
Jak jste z textu jistě pochopili, udržování vašeho webu je zásadní pro zachování jeho kvality a výkonnosti v očích vyhledávačů i vašich návštěvníků. Proto nepodceňujte ani odebírání stránek z indexu. Pokud si na to netroufáte, nemáte čas nebo chcete k SEO přistupovat komplexně, kontaktujte nás a naši odborníci zanalyzují jeho současný stav, navrhnou vylepšení a zařídí, abyste dosahovali dlouhodobě lepších a lepších výsledků.
Sdílet článek:



Odkaz byl vložen do schránky















